
At The Ohio State University, the study of ancient Northwest Semitic languages has moved out of the textbook and into the digital laboratory of epigraphic training. The recent graduate-led project on the Karatepe Inscription (KAI 26) serves as a prime example of how DEAPS (Digital Epigraphy and Archaeology Project) is redefining the pedagogical landscape for the 21st century, while simultaneously contributing a robust research environment for serious scholarship. Students in the Phoenician class at OSU have made available the first digital and free edition of the inscription of Azitiwada from Karatepe.

From Paper to Database
In a traditional classroom, a student might translate a passage once and never look at it again. Working within a digital database (DB) fundamentally changes the cognitive process. To build the entry for Azatiwada’s inscription, graduate students engaged in:
Iterative Preparation: The course is organized into units of textual preparation. Students are each assigned a set of inscriptions of roughly equal length. Their first task is to prepare a basic line-by-line edition and translation. The following week focuses on group preparation; working together, they ensure the Unicode text aligns with a standard published edition (in this case, Gibson’s) and reach a consensus on the translation. This forces students to immediately identify and debate linguistic difficulties.
Mass Tagging & Proofing: The next stage involves a detailed word-by-word tagging of the inscription. The class economizes this by using the database’s deterministic formulas to mass-tag lexical assignments and grammatical parsings based on the text itself. In teams, they then proof these parsings directly from the website. Each iteration forces the student to see the "big picture" of the content while simultaneously focusing on granular, difficult problems in the source. This inductive approach allows students to master Phoenician syntax through direct application.
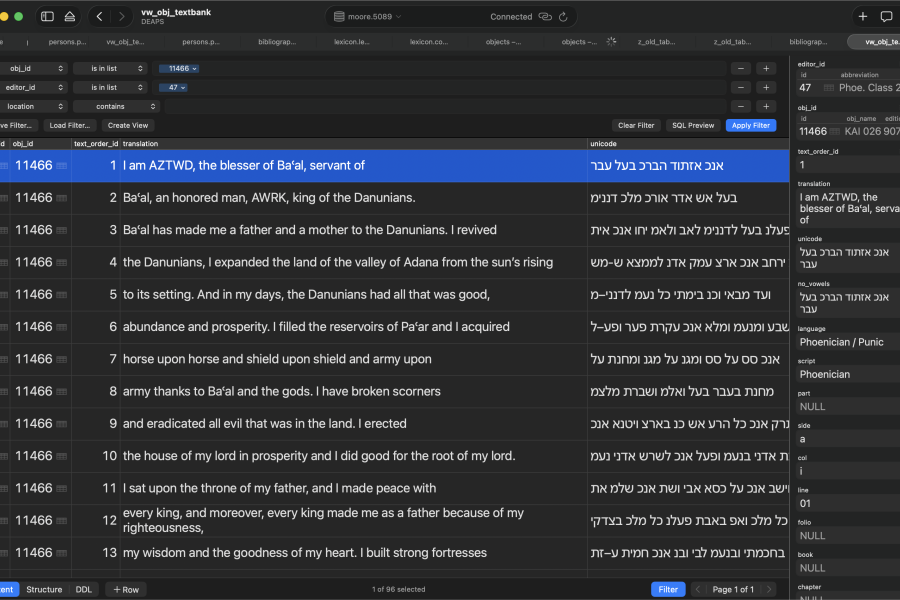
Collaborative Correction: The DB model encourages a "living" document where students peer-review and correct each other’s work, simulating the collaborative nature of professional epigraphy. Knowing their work is the only fully parsed, freely available edition of the Azatiwada inscription—accessible to the entire world—instills a level of precision and scholarly stakes rarely found in a classroom setting.
Holistic Engagement: Instead of looking at isolated letters, students must engage with the historical and archaeological context. To complete an entry, they must curate bibliographic sources and analyze photographs of the physical objects, ensuring the language is never divorced from its material history.
The Karatepe Dataset: A Bridge for the Initiate
KAI 26 is one of the longest and most significant Phoenician inscriptions in existence. For a student who has already gained competency in Hebrew or Syriac, it represents a simple yet challenging prospect for deciphering language in a real multilingual context:
Productive Redundancy: Because the text represents two Phoenician copies found at the site, the monumental inscription and the version on the skirt of the statue of the sun god, it is inherently repetitive. This is a gift to the initiate, allowing them to compare variants and fill in gaps where one copy may be damaged.
The Challenge of Grammar and Syntax: While the grammar contains several peculiarities, such as its expansive use of the infinitive absolute, it remains remarkably accessible. It allows students to see the "elasticity" of Northwest Semitic languages, and Phoenician in particular, within a bilingual context.
A Monumental Achievement
With a boastful appeal akin to Starship, Azatiwada's inscription declares that he "built this city" and dedicated it to the gods. In the hands of OSU graduate students, however, it has become an object of inquiry in a laboratory setting for scholarly training. By moving this text into the DEAPS database, these students aren't just reading Phoenician—they are building the digital infrastructure for the future of the field. The students who contributed to this entry are, in alphabetical order: Cody Beasley, Wyatt Rider, Armand Rogers, and Justin Wheaton.
Under the Hood: The DLATO Core
The technical foundation of this project is what sets it apart from traditional digital humanities work. Unlike many digital editions that rely on bulky, processed XML markup, DEAPS utilizes the DLATO Core Database structure. All data is curated within a PostgreSQL relational database. This move away from markup languages toward a structured SQL environment allows for incredible efficiency; the database can process complex linguistic queries almost instantly while remaining fully expandable. By training students to work directly in this backend environment, DEAPS is preparing the next generation of scholars to manage data with the same precision they will apply as professional scholars.
[Cover image generated by Gemini 3 (fast), corrected by ChatGPT (GPT-5)]